Eric Ettore (1-3), Felix Dörr (4), Nicklas Linz (4), Michal Balazia (5), Alexandra König (1,2,4)
1. Cobtek (Cognition-Behaviour- Technology) Lab, University Côte d’azur, Nice, France. 2. Centre de Mémoire de Ressources et de Recherche, Centre Hospitalier Universitaire Nice (CHUN), Nice, France. 3. Department of Psychiatry, Hopital Pasteur, CHU de Nice, 06000 Nice, France. 4. ki elements GmbH, Saarbrücken, Germany. 5. Institut national de recherche en informatique et en automatique (INRIA), Stars Team, Sophia Antipolis, Valbonne, France.
* Poster presented at the American Psychological Association Annual Meeting, USA
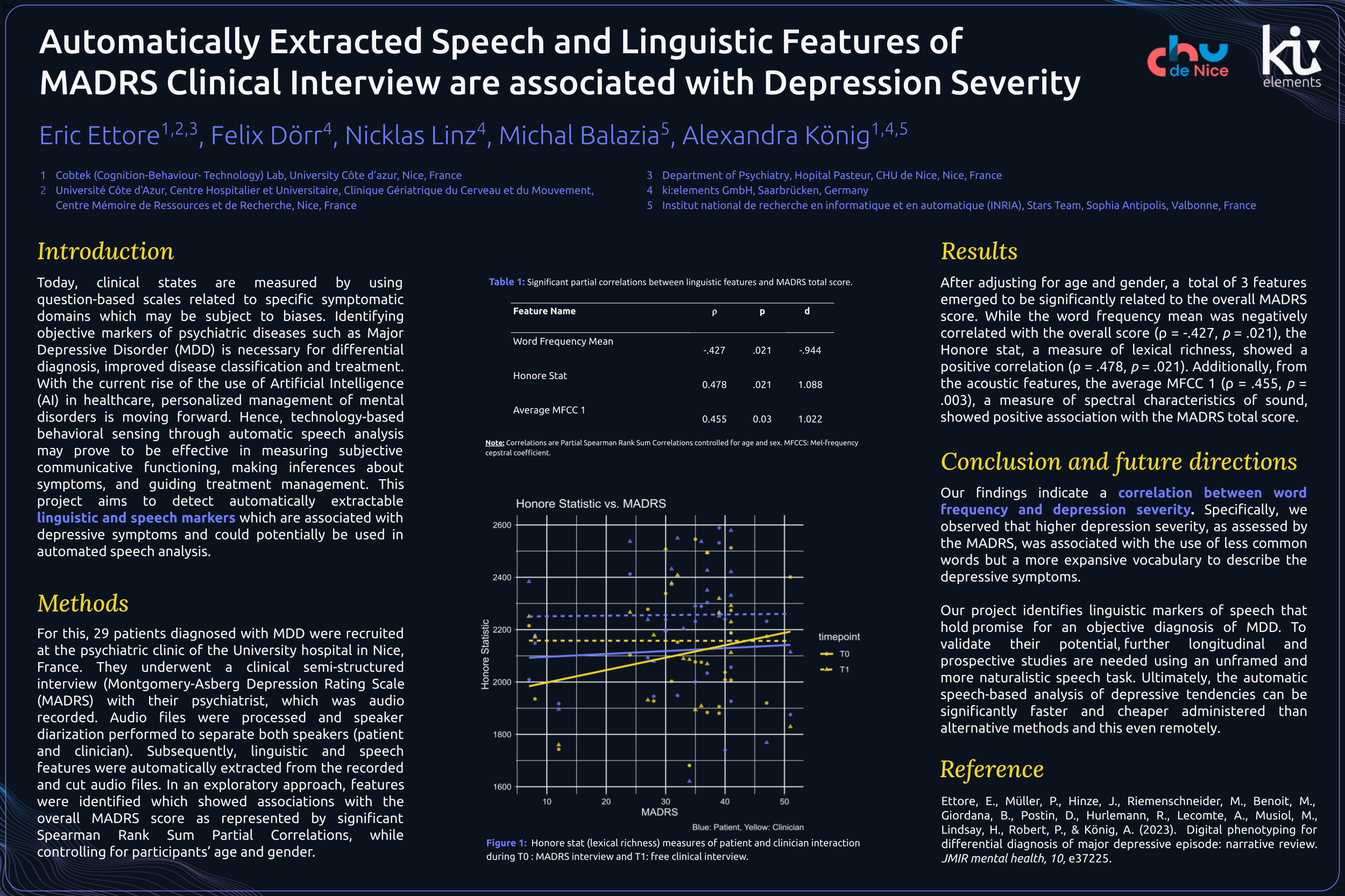
Background:. Today, clinical states are measured by using question-based scales related to specific symptomatic domains which may be subject to biases. Identifying objective markers of psychiatric diseases such as Major Depressive Disorder (MDD) is necessary for differential diagnosis, improved disease classification and treatment. With the current rise of the use of Artificial Intelligence (AI) in healthcare, personalized management of mental disorders is moving forward. Hence, technology-based behavioral sensing for instance through automatic speech analysis may prove to be effective in measuring subjective communicative functioning, making inferences about symptoms, and guiding treatment management. This project aims to detect automatically extractable linguistic markers which are associated with depressive symptoms and could potentially be used in automated speech analysis.
Methods: For this, 29 patients diagnosed with MDD were recruited at the psychiatric clinic at the University hospital in Nice, France. They underwent a clinical semi-structured interview (Montgomery-Asberg Depression Rating Scale (MADRS) with their psychiatrist which was audio recorded. Audio files were processed and speaker diarization performed to separate both speakers (patient and clinician). Subsequently, linguistic features were automatically extracted from the recorded and cut audio files. In an exploratory approach features were identified which showed associations with the overall MADRS score as represented by significant Spearman Rank Sum Partial Correlations while controlling for participants’ age and gender.
Results: After adjusting for age and gender, a total of 3 features emerged to be significantly related to the overall MADRS score. While the word frequency mean was negatively correlated with the overall score (ρ = -.427, p = .021), the Honore stat, a measure of lexical richness, showed a positive correlation (ρ = .478, p = .021). Additionally, from the acoustic features the average MFCC 1 (ρ = .455, p = .003), a measure of spectral characteristics of sound, showed positive association with the MADRS total score. Our findings indicate a correlation between word frequency and depression severity. Specifically, we observed that higher depression severity, as assessed by the MADRS, was associated with the use of less common words but a more expansive vocabulary to describe the depressive symptoms.
Conclusion: Our project identifies linguistic markers of speech that hold promise for an objective diagnosis of MDD. To validate their potential, further longitudinal and prospective studies are needed using an unframed and more naturalistic speech tasks. Ultimately, the automatic speech-based analysis of depressive tendencies can be significantly faster and cheaper administered than alternative methods and this even remotely.