Johannes Tröger 1, Elisa Mallick 1, Felix Dörr 1, Alexandra König 1, Ebru Baykara 1, Nicklas Linz 1, Juan Rafael Orozco-Arroyave 2
1) ki elements GmbH, Germany. 2) GITA Lab, Universidad de Antioquia, Medellín, Colombia.
* Poster presented at the AD/PD™ Alzheimer’s disease and Parkinson’s disease Conference 2024, Portugal
Abstract
Aims
Alzheimer’s Disease (AD) and Parkinson’s Disease (PD) are among the most common neurodegenerative diseases. They have some common underlying pathological mechanisms and also shared behavioral symptoms. It is common to characterize both diseases’ communalities and differences on a fluid biomarker level but less so using digital biomarkers such as speech or acoustics. The aim of this work is to investigate whether acoustic speech biomarker profiles from a standardized reading passage speech task can differentiate Alzehimer’s from Parkinson’s disease and associated behavioral clinical symptoms.
Methods
This feasibility research is based on two different Spanish reading speech data sets that are comparable but not based on the exact same protocol—the Dementia Bank IVANOVA first paragraph of Don Quixote (Ivanova et al., 2022) and the PC-GITA reading passage (Orozco-Arroyave et al., 2014). Both data sets recorded patients and matched healthy controls: IVANOVA (AD_dementia 54/ HC 155) and PC-GITA (PD 70 / HC 70). From the recordings, we extracted acoustic features using the ki:elements speech extraction library SIGMA. As the recording conditions vary and the demographic characteristics of the IVANOVA corpus is not provided, we normalized acoustic features for potential cohort effects (loudness normalization) and subsequently preselected acoustic features that do not show significant differences on their distributions when comparing the respective HC groups (e.g. speech_rate_HC_IVANOVA vs. speech_rate_HC_PC-GITA) using p = 0.20 as cutoff on the Two Sample Smirnov Test. We then combined those features in logistic regression models using 10-fold x-validation for better generalisability to simulate downstream clinical utility. The following scenarios were tested: AD vs. PD; AD vs. HC_pooled; PD vs. HC_pooled; HC_IVANOVA vs. HC_PC-GITA.
Results
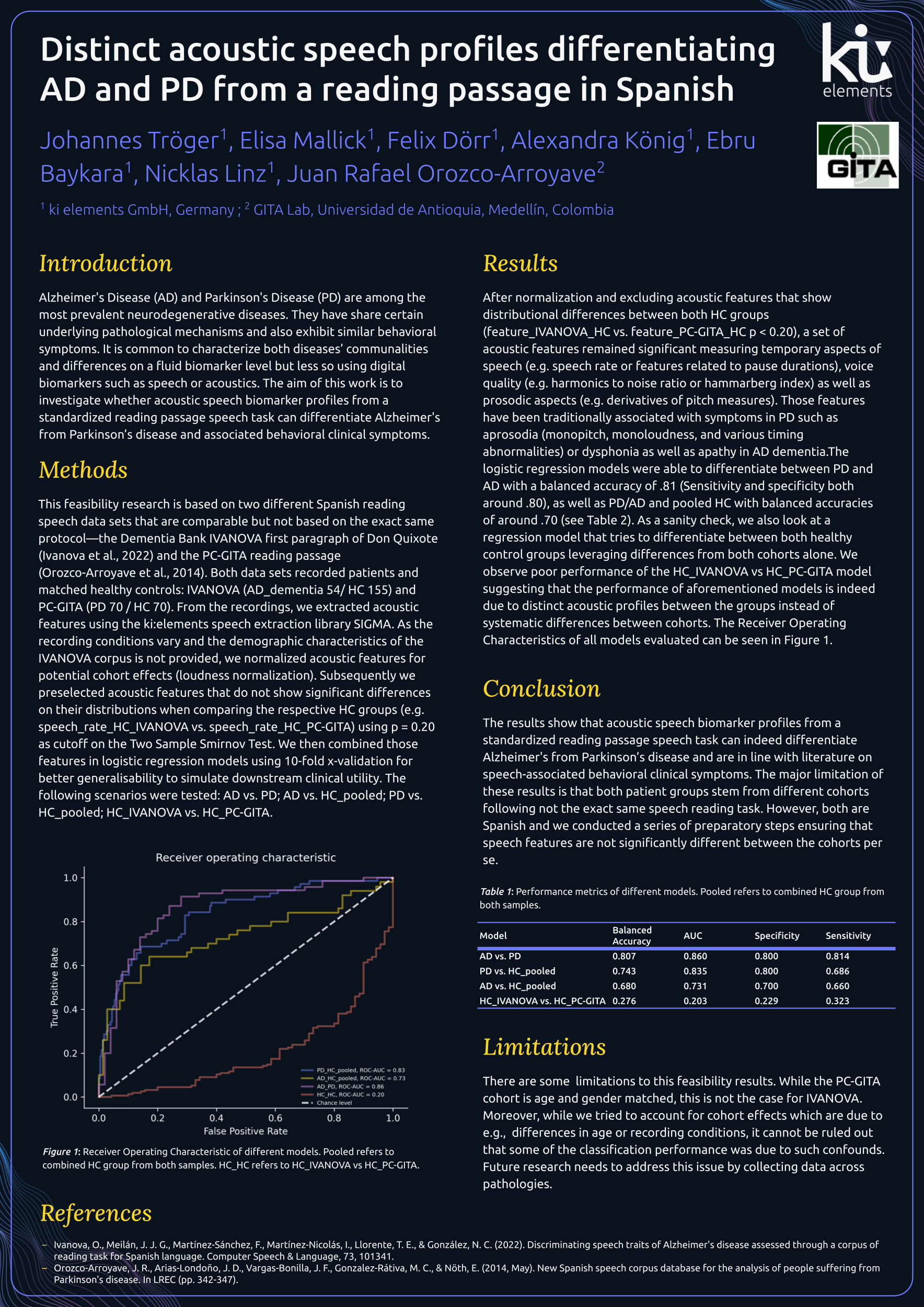
After normalization and excluding acoustic features that show distributional differences between both HC groups (feature_IVANOVA_HC vs. feature_PC-GITA_HC p < 0.20), a set of acoustic features remained significant measuring temporary aspects of speech (e.g. speech rate or features related to pause durations), voice quality (e.g. harmonics to noise ratio or hammarberg index) as well as prosodic aspects (e.g. derivatives of pitch measures). Those features have been traditionally associated with symptoms in PD such as aprosodia (monopitch, monoloudness, and various timing abnormalities) or dysphonia as well as apathy in AD dementia.
The logistic regression models were able to differentiate between PD and AD with a balanced accuracy of .81 (Sensitivity and specificity both around .80), as well as PD/AD and pooled HC with balanced accuracies of around .70 (see Table 1). As a sanity check we also look at a regression model that tries to differentiate between both healthy control groups leveraging differences from both cohorts alone. We observe poor performance of the HC_IVANOVA vs HC_PC-GITA model suggesting that the performance of aforementioned models is indeed due to distinct acoustic profiles between the groups instead of systematic differences between cohorts. The Receiver Operating Characteristics of all models evaluated can be seen in Figure 1.
Conclusions
The results show that acoustic speech biomarker profiles from a standardized reading passage speech task can indeed differentiate Alzehimer’s from Parkinson’s disease and are in line with literature on speech-associated behavioral clinical symptoms. The major limitation of these results is that both patient groups stem from different cohorts following not the exact same speech reading task. However, both are Spanish and we conducted a series of preparatory steps ensuring that speech features are not significantly different between the cohorts per se.
References
- Ivanova, O., Meilán, J. J. G., Martínez-Sánchez, F., Martínez-Nicolás, I., Llorente, T. E., & González, N. C. (2022). Discriminating speech traits of Alzheimer’s disease assessed through a corpus of reading task for Spanish language. Computer Speech & Language, 73, 101341.
- Orozco-Arroyave, J. R., Arias-Londoño, J. D., Vargas-Bonilla, J. F., Gonzalez-Rátiva, M. C., & Nöth, E. (2014, May). New Spanish speech corpus database for the analysis of people suffering from Parkinson’s disease. In LREC (pp. 342-347).